Structure Diagram Generation (SDG), 2D Layout, in the Chemistry Development Kit (Part 1)
Recent Bug Fixes and Improvements in the StructureDiagramGenerator (SDG) class of the Chemistry Development Kit (CDK) initiated a discussion on the need to refactor the CDK SDG code in order to make it more maintainable and extensible. This motivates me to write a series of blog items on the subject. This is the first one, with some general remarks on the topic and a basic overview on how the CDK SDG works.
I was extremely pleased when I read Rich Apodaca‘s remark on the SDG being the “crown jewel” of CDK and of course I think he’s right :-).
Chemoinformatics software frequently comes up with chemical structures in the form of connection tables without 2D or 3D coordinates. For those, 2D structure diagrams need to be produced in order to present them to the chemist on screen or on paper. Chemists have created rather uniform set of conventions on how these 2D diagrams should look like, as can be seen from a brief inspection of a regular organic chemistry book (we are talking Lewis notation here).
The process of producing 2D coordinates for coordinate-less chemical graphs is known as Structure Diagram Generation and has been extensively reviewed by Harold Helson of CambridgeSoft.
The state of the art has recently been set and published by Alex Clark et al in JCIM.
I wrote the CDK version of SDG in 2002 pretty much from scratch in just a few weeks and the code remained largely untouched since then. Before, I had used the only existing open source SDG code by Ugi and Dengler, MDRAW, which had been publish in printed form in the micro fiche edition of Journal of Chemical Research (M):2601-2689. Rich had blogged about SDG earlier this year and a couple of people commented on free versions of SDG. Be it as it is, the MDRAW code worked but was C and had other shortcomings, which made me start a Java version.
The basic components of SDG are quickly sketched:
- The connection table needs to be scanned for rings
- If rings are found, they need to be partitioned into ring systems.
- Ring systems are laid out individually. This is done by a class called the RingPlacer.
- For some bridged ring systems, no known algorithm leads to a good solution and therefore, a template mechanism is needed for them. In CDK, the TemplateHandler class does this job.
- Atoms which are ring substitutents are now attached to the laid out ring. If applicable, starting from those, chains are grown.
- If no rings exist, the longest chain is identified and laid out horizontally.
- Non-ring parts of the molecule are laid out in an extended geometry to avoid folding back onto the rest of the molecule. Layout of chain (non-ring) parts are performed
by the AtomPlacer class. - The above procedure may lead to overlap of atoms in the end. The OverlapResolver class checks for those clashes and tries to revolve them.
A result of this is shown for SMILES “C1=CC=C(C=C1)CC2CCC(CC2)CC56(C=3C=CC=CC=3C(C4=CC=CC=C45)C6)”.
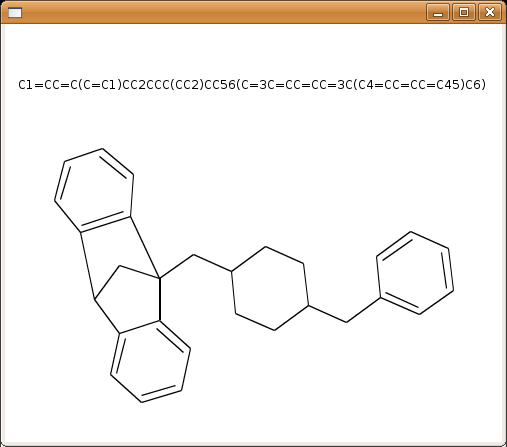
This simple set of rules yields very good results for more than 90% of all cases. The rest is a problem and, with respect to the algorithms on
the market, separates the men from the boys. CDK still plays in the junior league here, but does a decent job for the majority of layout problems.
I will continue this series later with insights into the various parts of the CDK SDG code. putty download windows
Categorised as: Chemoinformatics, Open Science
Some time ago I blogged about the MCDL applet [1], which does SDG too. To solve difficult cases, they use, just like the CDK, a template library. Now seen from the size of their template set (105), I think a good deal of this last 10% can be covered by the template functionality. I would be nice to see a breakdown into difficult ring systems for that 10% to see if indeed a modest template library can bring CDK’s success rate up to some 98%.
1.http://chem-bla-ics.blogspot.com/2006/08/small-java-applet-for-2d-structure.html
Talking about difficult cases, if you try the following SMILES at RG’s webservice at:
http://cheminfo.informatics.indiana.edu/~rguha/code/java/cdkws/cdkws.html#sdg
the layout of the rings could be improved…
[smiles] Ic1ccc(Nc2[nH0]c(N)[nH0][nH0]c2c2ccccc2)cc1
Noel, the layout problem that you describe was due to a bug which is fixed in CVS.